| S-BASIC internals
( S-Basic 1Z-013B )
|
||||||||||||||||||||||||||||||||||||||||||||
| Internal structure of a BASIC line | ||||||||||||||||||||||||||||||||||||||||||||
|
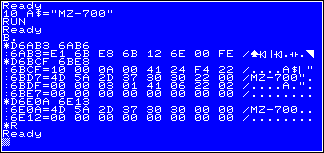
$6ABF is a pointer to the first byte of your BASIC program, the BASIC text area. Normally $6ABF points to $6BCF. All BASIC lines of a program are stored sequentially into this area starting from $6BCF. Each line contains a length field, a line number, an end of line character, and the information from the line. To this a simple example: 10 PRINT A$ The line number is 10, the command is PRINT, and the operator of the command is the string variable A$. The next line number is 20 and the command is a comment statement REM. The information found at $6BCF is as follows:
( "B." is the short form of the BASIC command BYE and this calls the monitor of the BASIC I've used to get displayed the contents of the storage starting from location $6BCF to location $6BE6. ) The first two bytes contain the length of the first basic line. The value is $0009.
The first BASIC line number is 10 and its hex value $000A follows the line length field at location $6BD1. $8F is a token that represents the PRINT command. A S-BASIC command isn't stored in its ASCII notation, it is stored in a "shortened form" of the command called token. When you enter a BASIC line all commands, functions, system variables, and operators of the S-BASIC's vocabulary will be tokenized by the interpreter before storing the line into the text area. That will speed up the interpreter's execution time when interpreting and executing the program. For this, the interpreter does a little bit more, we'll see later. The tokens can have one or two bytes only. Please, see my overview of all commands and its related tokens.
The space character from my source is stored too at location $6BD4. Eliminating space characters in a BASIC program reduces the amount of storage but makes it not easy to read. It will speed up the interpreter a little bit too while executing the program. The name of the string variable is stored at location $6BD5 and at least the end of line character $00 follows that name. At location $6BD8 begins the next BASIC line, $000C in length, having the line number 20, and a token $97 represents the REM command. The operator of this command, the comment "HELLO" is stored into the BASIC line. The line ends at location $6BE3. The two zeroes that follow represent the end of the program. The contents of the pointer at location $6AB3 can be used to find out the end of the last line stored by subtracting 3 or to find out the location for a next line to be stored by subtracting 2. This pointer points to the internal work area for all variables stored by the interpreter while executing a program. Normally this area follows immediately the text area. This was a simple overview how the interpreter stores a BASIC line into the text area. There are some specials more to know. The arithmetical part of the interpreter stores numeric constants by the floating point notation 6 bytes in length for each numeric constant into the text area. This will more speed up the interpreter when executing the program later. |
||||||||||||||||||||||||||||||||||||||||||||
| Internal structure of variables | ||||||||||||||||||||||||||||||||||||||||||||
|
Each type of a variable stored by the interpreter has its own format. I'll explain all formats of the variables now. There are several types of variables and they are stored sequentially by the interpreter in the order by their reference / occurrence during the execution of the BASIC program. The pointer $6AB3 points to the start of the variables area. Please take note of the following example: 10 A$="SHARP " "SHARP " and "MZ-700" are string constants stored into the BASIC line during the edit mode without further information but the quotes are stored too. The string constants remain unchanged in the BASIC line in their whole life. The only way to change them is to change them in the edit mode. While in edit mode no variable called A$, B$, and C$ will be stored. The names A$, B$, and C$ only will be stored into the BASIC line, no further information about the variable itself will be stored. The variable and its contents will be constructed and stored into the variables area only at the execution time of the BASIC program. While executing the program the interpreter is searching the variables area sequentially for a variable when a reference to a variable occurs by any command. If the variable is found it will be processed, if not, a new variable will be created. The search starts from the address that is pointed to by $6AB3. To create a new variable, the interpreter needs the address of the end of the variables area to expand it by appending the new variable. The address is pointed to by a pointer but this pointer points to the start of an area that follows the variables area immediately. The end of the variables area is added by an end character $00 and this is the address of the first free byte in case of the circumstance appending a new variable. Therefore the pointer points to the next not the first byte where the new variable is to store. The new variable is to store between the end of the variables area and the following area. This means the following area must be shifted up to get space for the new variable and the end character $00 of the variables area must be set at its new location, just behind the inserted new variable. Then the pointer must be updated. The pointer that points to the following area is located in $6AB5 and it points to the data area of string variables. A string variable stored in the variables area does not contain the data itself, it contains only a pointer to the data. I'll explain it later when you get more knowledge about the structure of the variables. The first byte of each variable definition is an ID-byte to identify the type of a variable. The ID byte is the attribute of a variable to identify its type by the interpreter. The following table shows all types of variables and their identification.
|
||||||||||||||||||||||||||||||||||||||||||||
| String variables ( ID $03 ) | ||||||||||||||||||||||||||||||||||||||||||||
| A string variable contains the ID $03 in its first
position. The length of the variable's name follows in one byte, for example,
the length of a string variable called AB$ is $02. The suffixed "$"-sign
isn't counted by the computation of the length of a variable's name. Next
the variable's name follows itself without having the suffixed "$"-sign
from the BASIC line. The BASIC line contains the full name suffixed with
the "$"-sign but no further information about the variable are
stored there.
The name is followed by one byte containing the length of the data stored in the string variable. A two byte data pointer follows that points to the string data contained in the string variable not directly but relative to the start of the variables data area. The start of the data area is contained in the pointer $6AB5. The interpreter finds the data by adding the relative pointer value found in the variable to the value contained in $6AB5. Here is an example:
In the example above a string variable A$ was built by: 10 A$="MZ-700". This BASIC line starts from location $6BCF in the length of $0010. The string variable A$ was stored into the variables area after the RUN-command was entered. The interpreter stored the variable into the variables area to the address pointed to by $6AB3. The pointer points to the start of the variables area $6BE1. The variable's ID is $03 and $01, the length of the name, is followed at location $6BE2. At location $6BE3 the name of the variable immediately follows this length field and next follows $06, the length of the data contained in A$. The following relative pointer's contents, i.e. $0222, must be added to the contents of the pointer $6AB5 that points to the beginning of the variables data area. The data can be found at: $6BE8 + $0222 = $6E0A. |
||||||||||||||||||||||||||||||||||||||||||||
| Numeric variables ( ID $05 ) and numeric constants ( ID $15 ) | ||||||||||||||||||||||||||||||||||||||||||||
| A numeric variable with the ID $05 appears only
in the variables area whereas a numeric constant with the ID $15 appears
only in a BASIC line. A numeric variable has the following structure:
The 1st byte contains the ID $05. The next byte contains the length of the name of the variable which follows this length field. Just behind the name is the value contained in the variable coded in the floating point format. A numeric constant in a BASIC line has no name and no name length field. It is a numeric constant defined in the BASIC line only without any name information. The floating point format in a BASIC line immediately follows the ID $15. The floating point format for both ID's is as follows: The length of it is 5 bytes. The 1st byte contains the exponent and his sign. The remaining 4 bytes contain the mantissa and the sign of the resulting value. The base of the values in the exponent and the mantissa is 2. The first bit ( bit 7 ) of the exponent contains the sign of the exponent. If bit 7 = 0 then the exponent is negative else positive. If bit 7 of the 1st byte of the mantissa = 1 then the resulting floating point value is negative else positive, but this appears only in the variables area, never in a BASIC line. In a BASIC line this bit is ever set to 0. The sign of a numeric constant in a BASIC line is given by the token prefixed to the ID $15. $F7 means positive ( + ) and can be omitted whereas $F8 means negative ( - ). The formula of the computation of a floating point value is as follows: 2E x ( 1 x 2-1 + n2 x 2-2 + n3 x 2-3 + ..... n32 x 2-32 ) E is the exponent and can be positive or negative as defined by its bit 7 ( 0 = negative, 1 = positive ). The exponent used in the formula is computed by the value in the first byte of the floating point value and the constant $80. The lower value is to subtract from the higher value. For example: If the exponent's byte contains $83 then $83 - $80 = 3 is used: 23. If the exponent's byte contains $00 then the resulting value of this floating point number is 0. This is an internal way to describe the zero value. The first bit of the mantissa is in use for the sign of the resulting floating point value, so 2-1 isn't lost by this it ever will be added by default ( see the formula above ). The remaining bits of the mantissa are bit 2 to 32. nx is the value of a bit from position x = 2 to x = 32. The possible range of this floating point construct is from 2.9387359E-39 to 8.5070592E+37. This range cannot be used in all modes of the MZ-700. This range is available for numeric constants in a BASIC line typed in while in edit mode. The information given by SHARP in the MZ-700's manual are: valid range from 1.548437E-38 to 1.7014118E+38. I didn't check it, but I think, the valid range is larger in some cases. Here is an example:
A numeric constant with an ID $15 was built while in edit mode by typing in the BASIC line 10 ( see $6BD5 ). The contents of this is 2E4 = 20,000 and can be found in the following floating point number starting at location $6BD6 in the length of 5 bytes. After the RUN-command was completed a variable A is stored by the interpreter into the variables area starting from location $6BDE. The type of the variable was set to $05 that means this is a numeric variable. The length of the name is $01 and the name itself follows at location $6BE0. Next the floating point value follows starting at location $6BE1 with its exponent containing $8F. Bit 7 of it is on that means the exponent is positive. The computation of the exponent results into: $8F - $80 = $0F and the interpreter will use 215. Remember to the formula above. The mantissa in this example contains $1C400000. The bit combination is: 0001 1100 0100.... remaining bits are 0 and not relevant. So I can use the bits set to 1 only in the formula, these bits are bit 4, 5, 6, and 10. The computation is as follows: 215 x ( 1 x 2-1 + 1 x 2-4 + 1 x 2-5
+ 1 x 2-6 + 1 x 2-10 ) The value is +20,000 because bit 7 of the 1st byte of the mantissa is 0. Try to set bit 7 on to get the same but a negative value. To this $1C is to replace by $9C while in S-BASIC's monitor and then leave the monitor and type in PRINT A. The result will be -20000. |
||||||||||||||||||||||||||||||||||||||||||||
| Line addressing ( ID $0B and $0C ) | ||||||||||||||||||||||||||||||||||||||||||||
| If you type in a line containing a branch command
like 'GOTO 50' or 'GOSUB 50' while in the edit mode the interpreter constructs
a variable 3 bytes in length containing the related line number ( i.e. $0032
). This variable is prefixed by the ID $0B and stored into the BASIC line
( i.e. $0B3200 ). The number of the line to branch to is stored with the
least significant byte first. This time, while in edit mode the interpreter
can't compute the line address. It may not exist or it can change while
editing a program.
So the interpreter must compute the line number into a real storage address while in execution mode. The computation takes execution time and will get more and more depending on the number of loops containing the relation to this line. To reduce the execution time by this inefficiency the computation is done only at the first occurrence and the line number variable with an ID of $0B will be replaced by the line address variable with an ID of $0C at this time. $0B indicates a line number while $0C indicates a line address. The interpreter replaces the two bytes containing the line number by the line address. The interpreter does not have to compute the address of the line again when executing this line next. If the interpreter finds the ID $0C while interpreting a line he can branch immediately to the address without any further address computation using the following two address bytes. If you stop the running program and edit it then at first all line addresses with the ID $0C are changed again into line numbers with the ID $0B. |
||||||||||||||||||||||||||||||||||||||||||||
| Hex values ( ID $11 ) | ||||||||||||||||||||||||||||||||||||||||||||
| A hex value is stored in three bytes. The first byte is the ID $11 and the next two bytes contain the hex value with the least significant byte first. For example $BFFF will be stored in the BASIC line as $11FFBF. This is a numeric constant having no name information and it appears in a BASIC line only. |